
آیا میدانستید که گوگل روزانه میلیونها درخواست خزش به وبسایتها ارسال میکند، اما بسیاری از این درخواستها صرف صفحاتی میشوند که هیچ ارزشی برای سئو ندارند؟
فایل کوچک اما استراتژیک robots.txt، کلید مدیریت این ترافیک خزندههاست؛ ابزاری که اگر بهدرستی تنظیم شود، بودجهٔ خزش را به سمت صفحات ارزشمند هدایت کرده و از هدررفت اعتبار سایت جلوگیری میکند. در این مقاله، از صفر تا صد این فایل حیاتی را بررسی میکنیم: از تعریف اولیه و تفاوت آن با تگ noindex، تا نحوهٔ ایجاد، دستورات کلیدی مانند Disallow و Crawl-delay، و روشهای رفع خطاهای رایج در سرچ کنسول.
اگر به دنبال بهبود عملکرد فنی سئو سایت خود هستید، این مطلب دقیقاً همان چیزی است که نیاز دارید. با ما همراه باشید تا گامبهگام، رمز و رازهای این فایل کوچک اما تأثیرگذار را کشف کنید.

فایل robots.txt چیست و چه نقشی در سئو سایت دارد؟
چیستی و هویت فنی:
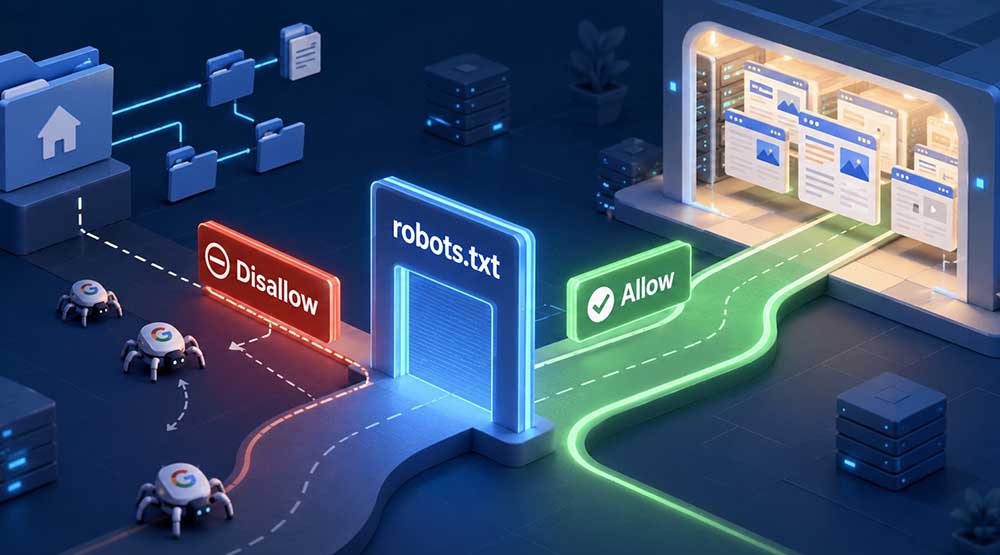
فایل robots.txt یک سند متنی مبتنی بر پروتکل استاندارد REP است که در ریشهٔ دامنه قرار میگیرد و وظیفهٔ هدایت رباتهای موتورهای جستجو را بر عهده دارد.
این فایل با ارائهٔ دستورالعملهایی به خزندهها، مشخص میکند که کدام بخشهای وبسایت برای خزش در دسترس هستند و کدام یک باید نادیده گرفته شوند.
اما نقطهٔ ظریف و حیاتی که در استراتژی سئو سایت باید به آن توجه کرد، این است که کدهای robots.txt یک مکانیسم اجباری نیست، بلکه صرفاً یک درخواست دوستانه از سوی وبمستر محسوب میشود؛ به همین دلیل، رباتهای مخرب معمولاً آن را نادیده میگیرند و نباید برای پنهانسازی اطلاعات حساس به آن تکیه کرد.
نقش کلیدی در بهینهسازی زیرساخت:
نقش اصلی robots.txt در بهبود سئو سایت، مدیریت هوشمندانهٔ «بودجهٔ خزش» است. گوگل برای هر دامنه سقف مشخصی از تعداد درخواستهای روزانه در نظر میگیرد و اگر این بودجه صرف خزش صفحات بیارزش مانند پیآیدیهای تکراری یا فیلترهای بینهایت شود، زمان کافی برای ایندکس صفحات اصلی باقی نمیماند.
با تنظیم دقیق این فایل، میتوان خزنده را از مسیرهای کماهمیت دور کرد و انرژی آن را به سمت محتوای ارزشمند هدایت نمود.
علاوه بر این، معرفی نقشهٔ سایت (Sitemap) در انتهای فایل، به گوگل کمک میکند تا معماری محتوای شما را سریعتر درک کند که این خود تأثیری غیرمستقیم اما ماندگار بر شاخصهای کلیدی سئو سایت خواهد داشت.
تأثیر بر ایندکس و هشدارهای اجرایی:
یک باور غلط رایج این است که robots.txt مستقیماً مانع ایندکس شدن صفحه میشود، درحالیکه این فایل فقط جلوی خزش را میگیرد. اگر صفحهای توسط این فایل مسدود شود، گوگل هرگز محتوای آن را نمیخواند و طبیعتاً در نتایج ظاهر نمیشود، اما این رفتار با تگ noindex تفاوت اساسی دارد.
از منظر سئو سایت، یکی از اشتباهات استراتژیک، بلاک کردن فایلهای CSS یا جاوااسکریپت است؛ زیرا گوگل برای رندرینگ صحیح به این منابع نیاز دارد و مسدودسازی آنها، کیفیت ارزیابی محتوا را مختل میکند.
بنابراین، robots.txt نقش یک تسهیلگر زیرساختی را ایفا میکند و تأثیر مستقیم بر رتبه ندارد، اما فقدان آن میتواند فرآیند ایندکسگذاری را با اختلال مواجه سازد.
فایل robots.txt چگونه بودجه خزش (Crawl Budget) سایت را بهینه میکند؟
تعریف بودجه و محدودیتهای آن:
در دانش سئو سایت، «بودجهٔ خزش» به تعداد صفحاتی گفته میشود که گوگل در بازهٔ زمانی مشخص (معمولاً روزانه) از وبسایت شما درخواست میکند و این عدد تحت تأثیر عواملی مانند سرعت هاست، نرخ خطاهای سروری و حجم محتوای ایندکسشده قرار دارد.
برای پروژههای بزرگ با بیش از دهها هزار صفحه، این بودجه به یک منبع حیاتی و کمیاب تبدیل میشود. اگر robots.txt بهدرستی پیکربندی نشود، گوگل مجبور خواهد بود بخش قابلتوجهی از این بودجه را صرف صفحات بینتیجه کند و در نتیجه، صفحات جدید یا بهروزرسانیهای مهم دیرتر کشف و ایندکس میشوند که این امر مستقیماً به ضرر استراتژی جامع سئو سایت تمام میشود.
ابزارهای پایش و اعتبارسنجی:
برای سنجش تأثیر robots.txt بر بودجه خزش، گزارش «آمار خزش» در گوگل سرچ کنسول بهترین مرجع محسوب میشود.
این گزارش نشان میدهد که گوگل چند صفحه را با موفقیت خزش کرده و چند مورد با خطا مواجه شده است. اگر مشاهده کردید که رباتها همچنان صفحات مسدودشده را درخواست میکنند (وضعیت Blocked by robots.txt)، باید دستورات را با استفاده از کاراکترهای wildcard بازنویسی کنید.
بهخاطر داشته باشید که تغییرات این فایل تا ۲۴ ساعت زمان نیاز دارد تا در شبکهٔ گوگل بازتاب یابد؛ بنابراین پس از بهروزرسانی، حتماً از ابزار تست مخصوص در سرچ کنسول استفاده کنید تا از صحت عملکرد آن پیش از تأثیرگذاری بر روی سئو سایت اطمینان حاصل کنید.
تفاوت فایل robots.txt با تگ noindex چیست؟
تفاوت در لایهٔ اجرایی خزش و ایندکس:
اصلیترین تمایز میان robots.txt و تگ noindex در لایهٔ عملکردی آنهاست؛ اولی در لایهٔ خزش عمل کرده و به ربات میگوید «این مسیر را درخواست نکن»، درحالیکه دومی در لایهٔ ایندکس عمل کرده و به موتور جستجو میگوید «این صفحه را بخوان اما در نتایج نمایش نده».
درک این تفاوت بنیادین برای هر متخصص سئو سایت الزامی است، زیرا اگر صفحهای با robots.txt مسدود شود، گوگل هرگز به تگ noindex درون آن صفحه دسترسی پیدا نمیکند.
این مسئله باعث میشود که صفحه همچنان از طریق لینکهای خارجی کشف و بهصورت «سایهوار» ایندکس بماند، درحالیکه هدف اصلی وبمستر حذف کامل آن از نتایج بوده است.

سناریوهای استفادهٔ صحیح از هر روش:
در استراتژی حرفهای سئو سایت، از robots.txt صرفاً برای مدیریت تردد رباتها استفاده میشود، نه برای حذف صفحات از نتایج. برای مثال، مسیرهای API، فایلهای موقت و صفحات داخلی که ارزش سئویی ندارند، با این فایل مسدود میشوند. در مقابل، تگ noindex برای صفحاتی کاربرد دارد که میخواهیم خزش شوند اما در نتایج نمایش داده نشوند؛ مانند صفحات حریم خصوصی، شرایط استفاده یا فیلترهای ترکیبی که محتوای تکراری تولید میکنند.
یک اشتباه رایج که به سئو سایت آسیب میزند، استفادهٔ همزمان از هر دو روش روی یک صفحه است که باعث سردرگمی خزنده و اتلاف بودجه میشود.
دستور Disallow در robots.txt؛ چه زمانی و چگونه استفاده کنیم؟
ساختار و نحوۀ نگارش دستور:
دستور Disallow در فایل robots.txt به خزنده اعلام میکند که از درخواست مسیرهای مشخصشده خودداری کند و این دستور همواره در کنار یک User-agent خاص تعریف میشود. برای مثال، User-agent: Googlebot و سپس Disallow: /private/ به گوگل میگوید که پوشهٔ خصوصی را نادیده بگیرد.
نکتهٔ فنی که در بهینهسازی سئو سایت باید مد نظر باشد، پشتیبانی این دستور از کاراکترهای جایگزین مانند * و $ است؛ اما تفسیر این کاراکترها در موتورهای جستجوی مختلف یکسان نیست. بهعنوان جایگزین ایمنتر، گوگل توصیه میکند برای مدیریت پارامترهای URL، بهجای Disallow از ابزار «تنظیمات پارامترها» در سرچ کنسول استفاده کنید تا دقت کنترل بیشتری داشته باشید.
زمانبندی طلایی برای استفاده (سناریوها):
موارد استفادهٔ هوشمندانه از Disallow در پروژههای سئو سایت عبارتند از:
۱) مسدودسازی کامل صفحات داخلی سیستمی مانند wp-admin یا cgi-bin که هیچ محتوای مفیدی برای کاربر ندارند؛
۲) جلوگیری از خزش محتوای تکراری ناشی از فیلترهای رنگ، اندازه یا قیمت در فروشگاههای اینترنتی؛
۳) بلاک کردن محیطهای آزمایشی (استیجینگ) که نباید در نتایج جستجو ظاهر شوند؛ و
۴) منع خزش فایلهای پشتیبان یا موقت که ارزش سئویی ندارند. اما هرگز از Disallow: / برای بستن کل دامنه استفاده نکنید، مگر در شرایط اضطراری (مثل توسعهٔ سنگین)، زیرا این کار باعث حذف تدریجی تمام صفحات از ایندکس گوگل و سقوط شدید سئو سایت خواهد شد.
چگونه خطای Blocked by robots.txt را در سرچ کنسول رفع کنیم؟
شناسایی ریشهٔ خطا در گزارشها:
خطای «Blocked by robots.txt» در بخش «پوشش ایندکس» گوگل سرچ کنسول نشاندهندهٔ این است که گوگل قصد خزش صفحهای را داشته، اما فایل robots.txt بهصورت صریح یا با استفاده از الگوهای wildcard آن را مسدود کرده است.
این خطا معمولاً در دستهٔ «ارسال شده اما ایندکس نشده» قابلمشاهده است و برای متخصص سئو سایت یک زنگ هشدار محسوب میشود. برای تشخیص دقیق، باید لیست صفحات متأثر را استخراج کنید و بررسی کنید که آیا این مسیرها را عمداً مسدود کردهاید یا خیر. بسیاری از اوقات، وبمسترها بدون آگاهی، مسیرهای عمومی مانند /product/*?filter را میبندند که ممکن است شامل صفحات اصلی فروش نیز باشد و بهطور ناخواسته به سئو سایت آسیب بزند.
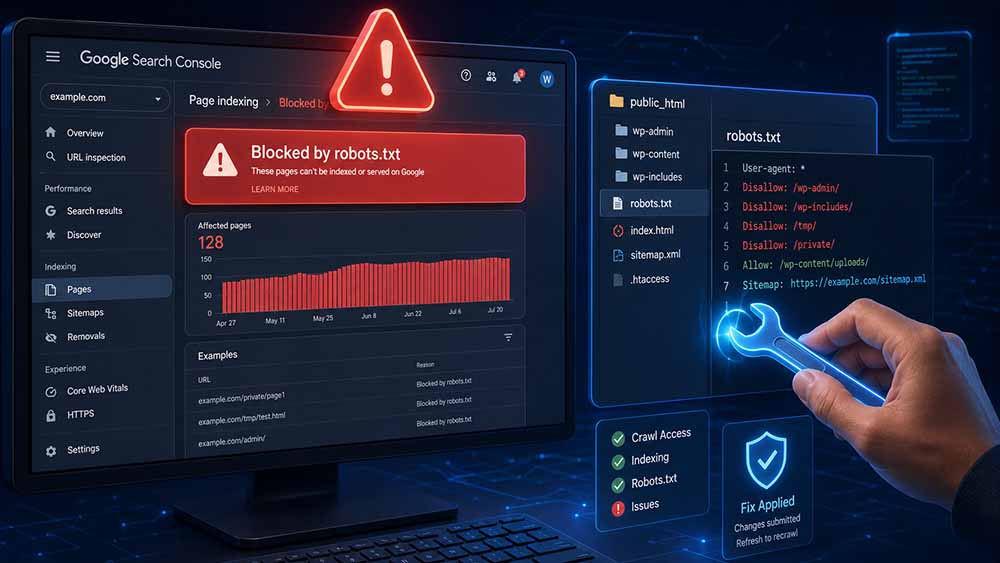
راهحلهای اصلاحی مبتنی بر هدف:
اگر صفحه نباید مسدود میشد، فایل robots.txt را ویرایش کرده و دستور Disallow مربوطه را حذف کنید؛ همچنین میتوانید با دستور Allow مسیر خاص را از شمول قوانین قبلی خارج کنید. پس از آپلود فایل جدید، در سرچ کنسول گزینهٔ «ارسال مجدد برای تأیید» را فعال کنید تا گوگل هرچه سریعتر تغییرات را اعمال کند. اما اگر صفحه باید مسدود میشد، میتوانید این خطا را نادیده بگیرید، زیرا رفتار مورد انتظار سیستم است.
با این حال، برای پاک کردن این خطا از گزارش، بهترین راهکار این است که صفحه را موقتاً با تگ noindex مشخص کنید تا گوگل ابتدا آن را بخواند و از ایندکس خارج کند و سپس مجدداً مسیر را با robots.txt مسدود کنید تا در آینده بودجهٔ خزش بر روی آن هدر نرود.
دستور Crawl-delay در robots.txt چیست و آیا گوگل از آن پشتیبانی میکند؟
کاربرد تاریخی:
دستور Crawl-delay یک فرمان غیراستاندارد و قدیمی در فایل robots.txt است که به خزنده اعلام میکند بین هر دو درخواست متوالی، به مدت مشخصی (معمولاً بر حسب ثانیه) توقف کند. هدف اصلی از این دستور، کاهش بار لحظهای روی سرورهای ضعیف و مدیریت پهنای باند مصرفی است.
برای مثال، مقدار Crawl-delay: 5 به ربات میگوید پس از هر درخواست، ۵ ثانیه صبر کند. گرچه این دستور توسط برخی موتورهای جستجوی کوچکتر و همچنین بینگ (Bing) پشتیبانی میشود، اما در مستندات رسمی گوگل بهصراحت اعلام شده است که این موتور جستجو از این دستور تبعیت نمیکند و آن را بهکلی نادیده میگیرد.
سیاست گوگل در قبال این دستور و جایگزین:
دلیل نادیده گرفتن Crawl-delay توسط گوگل، به الگوریتم پویای خزش این شرکت بازمیگردد که سرعت درخواستها را بر اساس عملکرد لحظهای سرور تنظیم میکند.
بهعبارت فنی، گوگل بهجای اتکا به دستورات دستی، از معیارهایی مانند «زمان پاسخگویی»، «نرخ تأخیر» و «کدهای وضعیت HTTP» برای تطبیق سرعت خزش استفاده میکند. بنابراین، در یک استراتژی مدرن سئو سایت، تکیه بر Crawl-delay برای کنترل گوگل کاملاً بینتیجه است و تنها ممکن است بر روی خزش بینگ یا یاندکس تأثیر بگذارد.
فایل robots.txt در کجای سایت قرار دارد و چگونه آن را ایجاد کنیم؟
مکان دقیق و ساختار دسترسی:
فایل robots.txt باید دقیقاً در ریشهٔ اصلی دامنه (که بهعنوان Root Directory شناخته میشود) قرار گیرد تا موتورهای جستجو بتوانند آن را پیدا کنند.
بهعنوان مثال، اگر دامنهٔ شما example.com است، این فایل باید از طریق آدرس مستقیم https://example.com/robots.txt در دسترس باشد و قرار دادن آن در زیرپوشهها (مانند public_html/subfolder/) کاملاً اشتباه است، زیرا گوگل فقط فایل ریشه را بررسی میکند. برای یافتن مکان فعلی، از طریق FTP یا مدیریت فایل هاست (مثل cPanel) وارد پوشهٔ اصلی (معمولاً public_html یا www) شوید و وجود آن را جستجو کنید.
اگر چنین فایلی وجود نداشته باشد، گوگل از قانون پیشفرض پیروی کرده و کل وبسایت را خزش میکند که ممکن است برای سئو سایت در سایتهای بزرگ مشکلساز شود.
روشهای ایجاد و ویرایش گامبهگام:
برای ایجاد، یک فایل متنی ساده با نام دقیق robots.txt بسازید (دقت کنید که نام فایل کاملاً بهصورت حروف کوچک باشد) و آن را با یک ویرایشگر کدنویسی مانند Notepad++ ذخیره کنید.
سپس محتوای دستورات موردنظر را نوشته و فایل را از طریق FTP در پوشهٔ ریشه آپلود نمایید. اگر از وردپرس استفاده میکنید، افزونههای قدرتمند سئو مانند Yoast یا Rank Math امکان تولید و ویرایش مجازی این فایل را از طریق پیشخوان فراهم میکنند؛ در این حالت، تغییرات از طریق رابط افزونه اعمال میشود و نیازی به آپلود دستی نیست.
اما توجه داشته باشید که این افزونهها معمولاً فایل فیزیکی روی سرور ایجاد نمیکنند و از طریق ریرایت به درخواستها پاسخ میدهند، بنابراین برای اطمینان از صحت کار، حتماً فایل را از طریق مرورگر تست کنید.

جمع بندی نهایی
robots.txt اگرچه تنها یک فایل متنی ساده در ریشهٔ دامنه است، اما نقشی بیبدیل در بهینهسازی زیرساخت فنی سئو سایت ایفا میکند. از مدیریت هوشمندانهٔ بودجه خزش و جلوگیری از هدررفت درخواستها روی صفحات بیارزش، تا تفکیک دقیق آن از تگ noindex و کاربرد صحیح دستورات Disallow، همه و همه نشان میدهند که این فایل، یک اهرم استراتژیک برای وبمسترهای حرفهای محسوب میشود.
همچنین، آگاهی از عدم پشتیبانی گوگل از دستور Crawl-delay و جایگزینی آن با ابزارهای رسمی سرچ کنسول، و نیز توانایی رفع خطای Blocked by robots.txt، از الزامات هر متخصص سئوست.
